
火车头数据采集平台1.6增加的Http正文提取,Ocr识别和中文分词功能
作者:小文 发布于:2012-9-14 17:31 Friday 分类:开发计划
9.12号发布的新版采集器平台增加了Http正文提取和Ocr识别功能,使用企业版本的用户都可以使用。用户可以通过调用http,完成正文识别或是ocr等功能,使用户的平台和采集器整合更加方便。以下是具体的使用方法,注意,请先启动http服务器。
1、正文提取功能
a.用户需要输入要提取的网址或是内容。如果是单纯的网址识别,注意要访问的网页不需要登录。
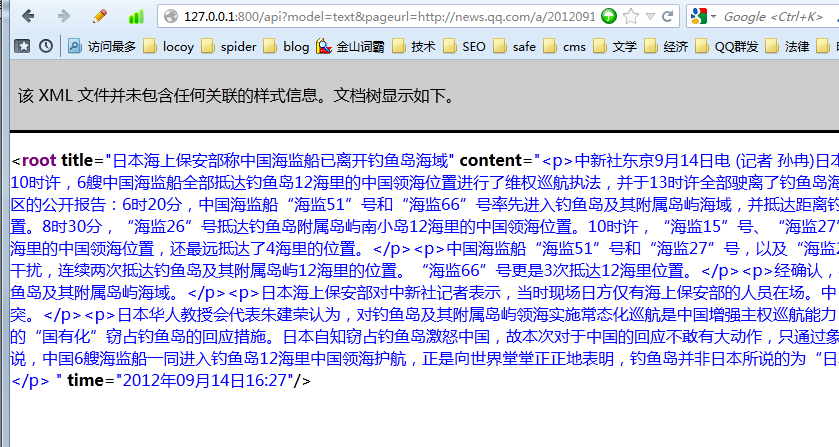
示例网址:http://127.0.0.1:800/api?model=text&pageurl=http://news.qq.com/a/20120914/001770.htm
b.如果是要提取某个网页的内容。请填写完整的html源码和pageurl.注意请求时对发送的内容进行utf8格式的urlencode.如果只填写了pageurl而没有html,则服务器会去访问pageurl请求html代码。
示例: http://127.0.0.1:800/api?model=text&html=编码后的完整的html代码&pageurl=http://news.qq.com/a/20120914/001770.htm
c.提取方式分为标准模式,完全模式,纯净模式,需要加一个returntype参数,其值为raw(标准模式),pure(纯净模式).默认为标准模式。
d.结构形式默认为普通文章,如果需要多层评论形式,请添加pagetype=bbs
最后返回的结果是xml格式的,如下
2.ocr识别
ocr识别支持直接传入图片地址和base64编码的图片。用户需要指定一个ocr配置文件名。ocr配置文件要保存在Configuration/ocr/目录下。请求的格式如下
a.直接的图片地址
http://127.0.0.1:888/api?model=ocr&ocrfile=baixing&imgurl=http%3A%2F%2Fstatic.baixing.net%2Fpages%2Fmobile%2FXTJ7aQPIUYmLpzNNsitnwA%253D%253D%2F2.jpg
返回的结果如下:

3.中文分词
中文分词支持一个或多个正文文本的识别,默认的是分词5个,分隔符,号。如果要修改,请传入参数splitnum和splitsep。识别文本的字段名要以wordsegtxt开头,整个字段名只能包含数字或字母。程序处理完后,会返回xml格式数据,以原字段名命令标签名。
http://127.0.0.1:888/api?model=wordseg&wordsegtxt1=%E7%81%AB%E8%BD%A6%E9%87%87%E9%9B%86%E5%99%A8(%E8%BD%AF%E8%91%97%E7%99%BB%E5%AD%970144474%E5%8F%B7%EF%BC%8C2009SR017475)%E6%98%AF%E4%B8%80%E6%AC%BE%E4%B8%93%E4%B8%9A%E7%9A%84%E7%BD%91%E7%BB%9C%E6%95%B0%E6%8D%AE%E9%87%87%E9%9B%86%2F%E4%BF%A1%E6%81%AF%E6%8C%96%E6%8E%98%E5%A4%84%E7%90%86%E8%BD%AF%E4%BB%B6%EF%BC%8C%E9%80%9A%E8%BF%87%E7%81%B5%E6%B4%BB%E7%9A%84%E9%85%8D%E7%BD%AE%EF%BC%8C%E5%8F%AF%E4%BB%A5%E5%BE%88%E8%BD%BB%E6%9D%BE%E8%BF%85%E9%80%9F%E5%9C%B0%E4%BB%8E%E7%BD%91%E9%A1%B5%E4%B8%8A%E6%8A%93%E5%8F%96%E7%BB%93%E6%9E%84%E5%8C%96%E7%9A%84%E6%96%87%E6%9C%AC%E3%80%81%E5%9B%BE%E7%89%87%E3%80%81%E6%96%87%E4%BB%B6%E7%AD%89%E8%B5%84%E6%BA%90%E4%BF%A1%E6%81%AF%EF%BC%8C%E5%8F%AF%E7%BC%96%E8%BE%91%E7%AD%9B%E9%80%89%E5%A4%84%E7%90%86%E5%90%8E%E9%80%89%E6%8B%A9%E5%8F%91%E5%B8%83%E5%88%B0%E7%BD%91%E7%AB%99%E5%90%8E%E5%8F%B0%EF%BC%8C%E5%90%84%E7%B1%BB%E6%96%87%E4%BB%B6%E6%88%96%E5%85%B6%E4%BB%96%E6%95%B0%E6%8D%AE%E5%BA%93%E7%B3%BB%E7%BB%9F%E4%B8%AD%E3%80%82%E8%A2%AB%E5%B9%BF%E6%B3%9B%E5%BA%94%E7%94%A8%E4%BA%8E%E6%95%B0%E6%8D%AE%E9%87%87%E9%9B%86%E6%8C%96%E6%8E%98%E3%80%81%E5%9E%82%E7%9B%B4%E6%90%9C%E7%B4%A2%E3%80%81%E4%BF%A1%E6%81%AF%E6%B1%87%E8%81%9A%E5%92%8C%E9%97%A8%E6%88%B7%E3%80%81%E4%BC%81%E4%B8%9A%E7%BD%91%E4%BF%A1%E6%81%AF%E6%B1%87%E8%81%9A%E3%80%81%E5%95%86%E4%B8%9A%E6%83%85%E6%8A%A5%E3%80%81%E8%AE%BA%E5%9D%9B%E6%88%96%E5%8D%9A%E5%AE%A2%E8%BF%81%E7%A7%BB%E3%80%81%E6%99%BA%E8%83%BD%E4%BF%A1%E6%81%AF%E4%BB%A3%E7%90%86%E3%80%81%E4%B8%AA%E4%BA%BA%E4%BF%A1%E6%81%AF%E6%A3%80%E7%B4%A2%E7%AD%89%E9%A2%86%E5%9F%9F%EF%BC%8C%E9%80%82%E7%94%A8%E4%BA%8E%E5%90%84%E7%B1%BB%E5%AF%B9%E6%95%B0%E6%8D%AE%E6%9C%89%E9%87%87%E9%9B%86%E6%8C%96%E6%8E%98%E9%9C%80%E6%B1%82%E7%9A%84%E7%BE%A4%E4%BD%93&wordsegtxt2=%E9%92%93%E9%B1%BC%E5%B2%9B%E6%98%AF%E5%8F%B0%E6%B9%BE%E7%9C%81%E4%B8%8D%E5%8F%AF%E5%88%86%E5%89%B2%E7%9A%84%E4%B8%80%E9%83%A8%E5%88%86

标签: ocr
OCR插件生成器(最后更新2014.06.11)
作者:小文 发布于:2012-5-8 15:05 Tuesday 分类:其它资源
火车采集器本身自带的ocr功能可以识别大部分常规的字母和数字。但在遇到特殊的字体时可能会出现部分识别错误。为此,我们将10版本带的按特征码识别的程序重新进行了修改,使其可以很方便的生成我们的C#插件。该程序可以单独运行。大家可以先打开自带的两个项目进行测试学习。需要注意的是:该工具只适用于那些字体字形固定的识别。

使用方法是:
1.输入一个图片地址,点击下载,使用图片显示出来
2.点击识别,对每个图片所对应的值进行校正后,点击ok,则该特征码将添加进去。
3.测试尽可能多的图片,使结果精确。
4.确认识别已无问题,点击工具菜单,点击编辑为插件,设置好生成dll的文件名,程序要识别的标签名,然后就可以在当前程序目录下生成一个dll文件。

5.在火车采集器中测试该插件
6.保存该项目,以便下次使用。
标签: ocr
关于OcrModule.exe打开时提示"由于应用程序配置不正确"错误的解决办法
作者:小文 发布于:2012-3-14 13:58 Wednesday 分类:常见问题
请按以下方法进行尝试修复。
方法一:http://zhidao.baidu.com/question/294189582.html
是由于Microsoft Visual C++ Redistributable Package 出问题造成的。 Microsoft Visual C++ 2008 Redistributable Package (x64) 安装 Visual C++ 库的运行时组件,使用户能够在未安装 Visual C++ 2008 的计算机上运行使用 Visual C++ 开发的 64 位应用程序。(注:飞信出问题就是这玩意出错咯,重装一下就ok)
用这个补丁:http://download.microsoft.com/download/5/9/e/59e74271-2b59-49a1-b955-96b69cc34f38/vcredist_x86.exe
注意版本不同,使用的补丁也不同。
方法二:http://jingyan.baidu.com/article/454316abb9e750f7a7c03a2a.html
标签: ocr
火车采集器通用OCR识别.NET插件(03-21更新)
作者:小文 发布于:2011-3-28 11:26 Monday 分类:官方公告
继火车头通用OCR识别/验证码识别演示程序
发布之后,我们将该技术做成通用插件,引用到火车采集器中来,供舰版及企业版用户直接免费使用
1、特殊注意:该插件需要 Microsoft Visual C++ 2008 SP1 Redistributable 支持。
Visual C++ 2008 SP1 Redistributable下载地址:http://www.microsoft.com/downloads/zh-cn/details.aspx?FamilyID=a5c84275-3b97-4ab7-a40d-3802b2af5fc2
2、该压缩包只是火车采集器插件,如果需要配置插件需要的xml配置文件,请使用火车头通用OCR识别/验证码识别演示程序(http://board.locoy.com/?post=69
)进行测试识别和配置xml。
3、安装使用方法(火车采集器2010版以上适用):
安装方法:将压缩包里面的System目录及Plugins目录覆盖到火车采集器程序目录内
该ocr也能识别部分非常简单的汉字,如果测试程序配置后可以识别,需要将测试程序里面的chi_sim.traineddata复制到采集器目录下System/tessdata目录下。
使用方法:1.使用火车头通用OCR识别/验证码识别演示程序(http://board.locoy.com/?post=69
)进行测试识别并保存xml配置文件到火车采集器Plugins目录,文件名必须包含识别二字, 如:口碑验证码识别.xml,58同城验证码识别.xml。
2.假设您已经识别测试成功,开始添加图片地址标签,该标签名为您刚刚保存的xml文件的文件名 如:口碑验证码识别,58同城验证码识别。
3.测试识别效果或正式采集。
旗舰版企业版用户可以直接免费使用,请直接向您所属客服索要该识别插件。

标签: ocr
联系我们
联系电话
-
0551-62864156
QQ邮件订阅

最新评论
- industrialegy
<a href="http://www.... - inve
这个采集到的视频地址 应该不是真实地址... - 云南桥架厂
我能说这个妹不错么 - 密密麻麻
win10 64位,处理后会留下原压缩包... - 平行进口车
以前经常用火车,来支持一下。 - 天津网站建设
文章采集器,厉害了 - 骗子医院
这个可以试试! - qq昵称
这么好的帖子,必须顶起来!! - 哈尔滨舒家网
试用一下,看是否能用。希望能用。火车头业... - 誉非
这个下载下来是安装程序,不是视频教程啊。
