
火车采集器V9.2起将支持Python插件
作者:小文 发布于:2016-5-26 9:25 Thursday 分类:官方公告
除了支持PHP,C#插件,最近火车采集器终于又迎来了一个新的插件,Python插件。用户可以在自己的Python插件中,修改html代码,修改最终采集结果,可以实现更多自己的想法。python插件支持2.7和3.x版本,采集器默认自带2.7和3.4的示例代码,用户只需要稍微修改即可以完成自己的功能。Python插件功能将在V9.2版本中集成,马上就能和大家见面了。更多插件及开发,请加QQ群 火车头开放平台 149855485
以下是3.4的python插件示例代码
import sys,importlib
from urllib import parse
import json
if len(sys.argv)!= 5:
print(len(sys.argv))
print("命令行参数长度不为5")
sys.exit()
else:
LabelCookie = parse.unquote(sys.argv[1])
LabelUrl = parse.unquote(sys.argv[2])
#PageType为List,Content,Pages分别代表列表页,内容页,多页http请求处理,Save代表内容处理
PageType=sys.argv[3]
SerializerStr = parse.unquote(sys.argv[4])
if (SerializerStr[0:2] != '''{"'''):
file_object = open(SerializerStr)
try:
SerializerStr = file_object.read()
finally:
file_object.close()
LabelArray = json.loads(SerializerStr)
#以下是用户编写代码区域
if(PageType=="Save"):
if(LabelArray['标题']):
LabelArray['标题']='这是Python插件处理的标题'
else:
LabelArray['Html']='当前页面的网址为:'+ LabelUrl +"\r\n页面类型为:" + PageType + "\r\nCookies数据为:"+LabelCookie+"\r\n接收到的数据是:" + LabelArray['Html']
#以上是用户编写代码区域
LabelArray = json.dumps(LabelArray)
print(LabelArray)
号外:火车浏览器打码插件开源开放了
作者:小文 发布于:2016-5-26 9:09 Thursday 分类:官方公告
号外:火车浏览器打码插件开源开放了,优优云,若快,GSA,联众,云速打码,DeCaptcher全部开放,全部源码。开发者可以按示例迅速集成自己的打码平台。源码及开发注意事项请看附件火车采集器V7C#插件开发说明
作者:小文 发布于:2012-3-7 13:14 Wednesday 分类:官方公告
火车采集器V7的C#插件进行了比较大的更改。为了方便用户更快的上手,我们提供了大量的代码示例。请各位需要开发的朋友打开采集器 Extensions\LocoySpider\Develop 目录下的项目,研究学习。标签: 插件
火车头数据采集平台插件开发说明
作者:小文 发布于:2012-3-7 10:21 Wednesday 分类:其它资源
请下载附件中的代码示例和使用说明。代码示例为Shopex图片上传插件。
使用php插件应对不同格式的分页样式
作者:小文 发布于:2011-6-1 14:59 Wednesday 分类:软件培训
有的网站使用多种模板显示分页地址,这种情况下我们要获取分页地址就非常困难了。不过我们可以通过插件的功能,自己编写程序判断并生成分页的地址,然后让采集器去获取到。我们的例子如下:
本次测试的网址:
http://www.diyifanwen.com/fanwen/lunwenzhidao/1141715512857992.htm
http://www.diyifanwen.com/fanwen/zhuchici/20101011222334115874624.htm
我们分析其分页地址,可以看到不同的分页样式和代码
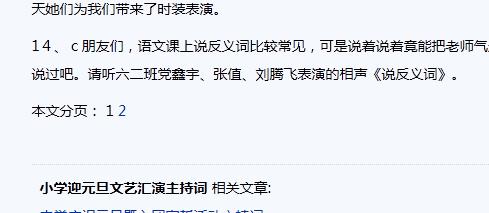



对于这种基本没规律的分页,我们无法判断分页的区域,也无法直接得知其总分页数,该怎么办呢?
经分析可以得知,分页的规律是在原网址后加上分页页码,如 默认页是1141715512857992.htm,则分页是 1141715512857992_2.htm 。因为这个分页是全部列出的,我们就有办法了:可以去循环查找是否有分页地址存在,有存在则说明有这个分页,然后我们生成存在的网页地址即可。我们用php来写插件。

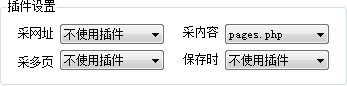
插件中判断了当前页面类型,然后对整个内容页代码进行修改,生成有分页的代码。
在采集器中,插件使用位置如下
最后的结果如下
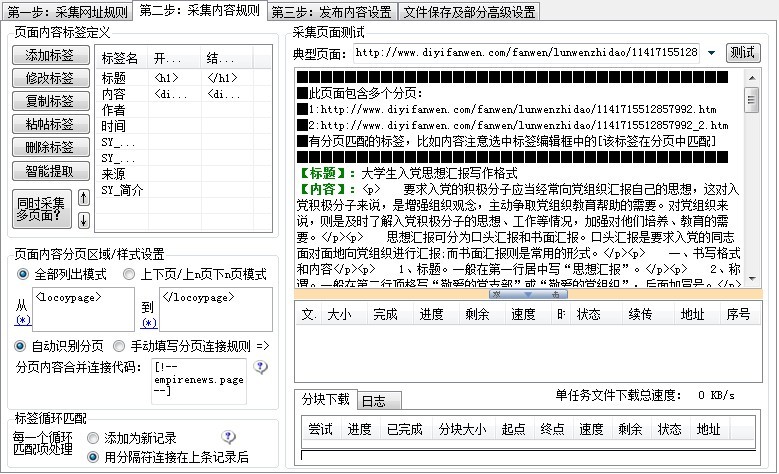
注意设置这里的分页区域和插件中的一致。
到这里,这个分页的处理就完成了。
如果我们有时遇到更复杂的怎么办,如 无法确认有几个分页,是上下页模式的,这时用插件可以使用笨办法,先探测一下下一页是否存在,如果存在则加入,不存在就跳过。
附件中为本次的规则和插件。大家可以再研究一下。
联系我们
联系电话
-
0551-62864156
QQ邮件订阅

最新评论
- industrialegy
<a href="http://www.... - inve
这个采集到的视频地址 应该不是真实地址... - 云南桥架厂
我能说这个妹不错么 - 密密麻麻
win10 64位,处理后会留下原压缩包... - 平行进口车
以前经常用火车,来支持一下。 - 天津网站建设
文章采集器,厉害了 - 骗子医院
这个可以试试! - qq昵称
这么好的帖子,必须顶起来!! - 哈尔滨舒家网
试用一下,看是否能用。希望能用。火车头业... - 誉非
这个下载下来是安装程序,不是视频教程啊。
