
火车采集器插件功能详解
作者:小文 发布于:2010-9-24 11:29 Friday 分类:软件培训
火车采集器2010版增加了多处插件处理点,可以更方便用户的二次开发.
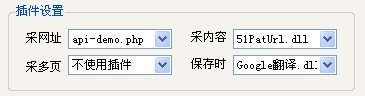
对于各部分插件的说明及使用方法如下:
1.采网址:
该处的插件可以对1级,2级网址的采集起作用(也就是说0级网址的采集不会使用插件).插件会对火车采集器0级,1级网址请求回来的html代码进行处理,处理完的html代码交给采集器,采集器再进行网址提取和过滤.
需要注意的问题是如果您使用了2级网址采集,在插件处理0级或是1级网址所请求回来的代码时,您需要自己分析请求的网址和内容,从而知道您到底是处理0级还是1级html内容处理.
2.采内容:
该处的插件是采集器将默认页源代码下载完成后,将整个html代码交给插件处理.插件可以对html代码进行添加,删除等操作.比如默认页中有js脚本生成动态网址,您需要多页采集这个动态网址内的内容,则可以写程序生成 多页地址,然后用采集器去获取其中的地址,然后用采集器的多页功能处理.比如有些动态生成的下载地址,您可以写程序生成,然后用采集器获取并下载.
3.采多页:
该处的插件是采集器将多页代码下载完成后,将整个html代码交给插件处理.然后采集器再从处理后的代码中分析获取标签内容,下载文件等操作.
需要注意的一点是,如果有多个多页,每个多页地址采集器都会处理.对于插件如何知道自己在处理哪个多页,请根据传入的网址及内容由开发者写代码判定.
4.保存时:
该处的插件是采集器已完成标签的提取,文件的下载,然后在保存到数据库之前所做的处理.该插件传入的参数和其它三个插件不是,它是一个数组,是标签名对应标签值的组合.用户可以在这里对标签的值进行处理,比如价格的计算,单位的转化.该插件的操作位于火车采集器标签的不符合内容处理前,因此,您也可以设定标签的值为特定的值,从而实现不保存或是删除该记录的功能.如果您设置了数据库中不得有重复记录,也可以使用该插件,实现有不得重复的数据的处理.
一个插件可以同时包含其它的页面的代码.如可以有处理列表网址页的代码,也可以有处理保存时的代码.具体的调用请参见开发示例.
PHP插件及C#插件的开发非常简单,具体请参见默认的开发示例.在插件管理器中,选择新建插件,即可以看到默认的开发环境及说明.
标签: 插件
评论:


联系我们
联系电话
-
0551-62864156
QQ邮件订阅

最新评论
- industrialegy
<a href="http://www.... - inve
这个采集到的视频地址 应该不是真实地址... - 云南桥架厂
我能说这个妹不错么 - 密密麻麻
win10 64位,处理后会留下原压缩包... - 平行进口车
以前经常用火车,来支持一下。 - 天津网站建设
文章采集器,厉害了 - 骗子医院
这个可以试试! - qq昵称
这么好的帖子,必须顶起来!! - 哈尔滨舒家网
试用一下,看是否能用。希望能用。火车头业... - 誉非
这个下载下来是安装程序,不是视频教程啊。

2011-11-19 22:40