
PHP采网址(列表页处理)插件的开发方法
作者:小文 发布于:2010-9-15 11:12 Wednesday 分类:软件培训
火车采集器中列表页插件是用来处理采网址时采集的网页源代码的.插件可以对源代码进行处理,然后采集器从处理过的代码中分析网址或是采集数据和网址.
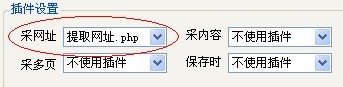
今天我们以采集 http://news.hexun.com/ 的网址为例,比如我们只采集包含有当天日期的网址,比如今天是 2010-09-15,那么只有网址中有这个日期代码的才可以被我们采集到.
我们的处理思路就是用插件提取所有符合条件的网址,然后生成链接地址,那么,最后采集器采集到的网址就是符合条件的网址了.
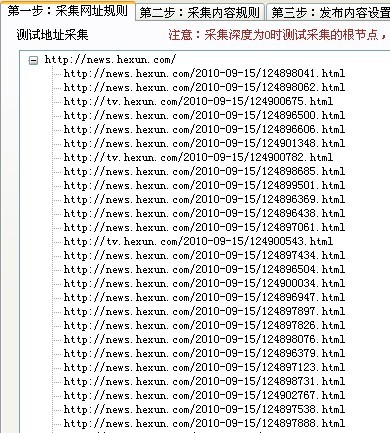
具体请看插件代码
<?php
/*
*火车采集器外部编程接口处理标签内容示范文件
*该文件内自动系统的三个参数$LabelArray $LabelCookie,$LabelUrl
*对任意采集的标签都适用请对标签内容处理后直接将该数组serialize($LabelArray)输出,
*采集器内部即可接收到该标签的内容,对比以前的接口规则,新规则可以实现标签之间的数据调用和处理
*参数说明:
*$LabelArray - 标签名及标签内容集合 结构如:Array('栏目id' => 2,'出处'=> 'www.locoy.com','作者'=>'火车采集器','内容'=>'<center><b>暴笑短信') ##
*$LabelCookie - 对应采集中用到的Cookie值
*$LabelUrl - 当前采集的页面的Url地址
* 特别注意:如果是处理列表页,默认页,多页时会有以下两个标签
$LabelArray['Html'] 网页的源代码,没有经过采集器处理的,直接下载后的数据.修改这里的数据,请将新值赋予$LabelArray['Html']
$LabelArray['PageType'] 值可能为 List, Pages, Content 分别代表处理列表页,多页,默认页
* @Copyright Copyright (c) 2005-2010 http://www.locoy.com
* @Version LocoySpider 2010 or later
* @Licence Support On LocoySpider Standard and Enterprise Edition
*以上语句建议不更改,以下为用户操作区域 该区域只限对数组值进行操作,不得有打印输出产生,不得直接增加或删除相应标签名
*/
if($LabelArray['Html'])
{
if($LabelArray['PageType']=='List')
{
$urlArr=array();
$html=$LabelArray['Html'];
$today=date("Y-m-d",time());
preg_match_all("/href=\"([^\"]*?\.html)\"/",$html,$mcs);
//var_dump($mcs);
if(count($mcs)>0)
{
foreach($mcs[1] as $url)
{
if(strpos($url,$today)>0) $urlArr[]=$url;
}
$LabelArray['Html']='<a href="'.implode('"><a href="',$urlArr).'">';
}
}
}
//#############以上为用户操作区域#############################################################################################################################
//#############以下语句必须保留,建议不更改###################################################################################################################
//ob_clean();
echo serialize($LabelArray);
?>
评论:





联系我们
联系电话
-
0551-62864156
QQ邮件订阅

最新评论
- industrialegy
<a href="http://www.... - inve
这个采集到的视频地址 应该不是真实地址... - 云南桥架厂
我能说这个妹不错么 - 密密麻麻
win10 64位,处理后会留下原压缩包... - 平行进口车
以前经常用火车,来支持一下。 - 天津网站建设
文章采集器,厉害了 - 骗子医院
这个可以试试! - qq昵称
这么好的帖子,必须顶起来!! - 哈尔滨舒家网
试用一下,看是否能用。希望能用。火车头业... - 誉非
这个下载下来是安装程序,不是视频教程啊。

2016-08-17 22:25