
齐博cmsv7.0文章发布模块发布
作者:小文 发布于:2011-4-16 14:18 Saturday 分类:其它资源
齐博CMS v7 文章发布模块使用说明
一、使用教程
1.文字教程
1.1、导入发布模块 齐博CMS v7 文章发布模块.cwr 到采集器或是直接复制该模块到采集器的Module目录.
1.2、如您需要设置一些特定参数,请参照参数说明修改模块.
1.3、设置发布配置,如测试成功,保存发布配置.
1.4、在任务发布中选中web布配置,然后采集并开始发布.
2.参考教程
下载地址:http://video.locoy.com/module/dede/dede56_article.7z
二、注意事项
1、该模块仅适用于发布文章到齐博CMS频道内容模型为普通文章的栏目;
2、分页代码 [-page-]
3、网站根地址为后台管理目录,默认的为admin.发布配置根地址设置示例: http://qibov7.cn/admin
三.参数说明
1、必选参数
fid= 分类ID
postdb[title] 标题
postdb[content] 内容
postdb[yz]=1 审核
2、可选参数:
postdb[smalltitle] 简短标题
postdb[titlecolor] 标题样式颜色
postdb[author] 作者
postdb[copyfrom] 出处
postdb[copyfromurl] 出处网址
postdb[picurl] 缩略图
postdb[automakesmall] 1为系统自动截图
picWidth 手工截图宽,默认200
picHeight 手工截图高,默认150
postdb[keywords] 关键字
postdb[posttime] 日 期
postdb[begintime] 开始浏览日期
postdb[endtime] 结束浏览日期
postdb[hits] 点 击
postdb[passwd] 密码
postdb[money] 收费(整站积分)
postdb[description] 文章简介
postdb[subhead] 副标题
ExplodePage 0 分页1自动,-1手动,0不分,手工分页符[-page-]
PageNum 3000 自动分页字数
GetOutPic 1为将文章中的外部图片采集回来
postdb[levels] 推荐
postdb[target] 新窗口打开
合肥乐维信息技术有限公司
小文
2011.4.16
标签: 齐博cms
火车头通用OCR识别/验证码识别演示程序
作者:火车头 发布于:2011-3-9 15:16 Wednesday 分类:其它资源
引言:
OCR技术是光学字符识别的缩写(Optical Character Recognition),是通过扫描等光学输入方式将各种票据、报刊、书籍、文稿及其它印刷品的文字转化为图像信息,再利用文字识别技术将图像信息转化为可以使用的计算机输入技术。可应用于银行票据、大量文字资料、档案卷宗、文案的录入和处理领域。适合于银行、税务等行业大量票据表格的自动扫描识别及长期存储。相对一般文本,通常以最终识别率、识别速度、版面理解正确率及版面还原满意度4个方面作为OCR技术的评测依据;而相对于表格及票据, 通常以识别率或整张通过率及识别速度为测定OCR技术的实用标准。
OCR识别在网站上广泛用于小幅图片的文本提取和验证码识别,以前很多识别程序都是基于特定网站,特定图片进行特征码分析。合肥乐维信息技术公司根据此前的技术积累,构架通用识别方案,做成此演示程序供大家测试。希望大家积极提供宝贵的测试意见,以便我们应用到软件开发中,服务广大站长。
该演示程序需要.net framework2.0 及支持 Microsoft Visual C++ 2008 SP1 Redistributable 支持。
.net framework2.0下载地址:
32位下载地址:http://download.microsoft.com/download/5/6/7/567758a3-759e-473e-bf8f-52154438565a/dotnetfx.exe
64位下载地址:http://download.microsoft.com/download/a/3/f/a3f1bf98-18f3-4036-9b68-8e6de530ce0a/NetFx64.exe
Visual C++ 2008 SP1 Redistributable:http://www.microsoft.com/downloads/zh-cn/details.aspx?FamilyID=a5c84275-3b97-4ab7-a40d-3802b2af5fc2
直接打开 LeWellOCR.exe 运行演示程序
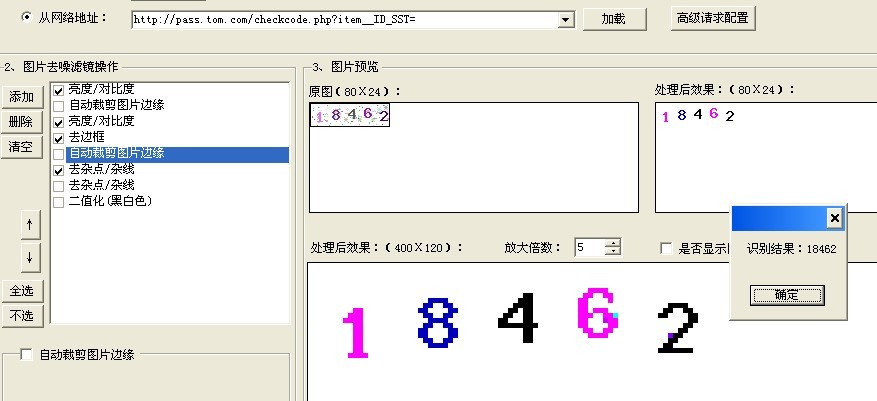
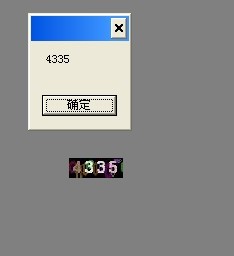
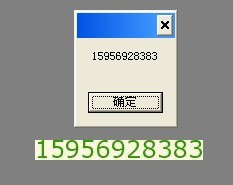
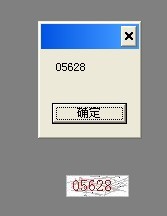
1、从本地或者指定URL地址 打开需要识别的图片
2、可选是否对图片进行一些简单的处理操作,如果需要请添加滤镜对图片进行去噪
3、设置白名单和黑名单字符串,即允许和不允许在结果中出现的字符串
4、开始测试识别!
内置了几个基础的测试样式大家可以直接在项目中加载测试。
58同城验证码识别.xml,
454.cn验证码识别.xml,
ageow.com验证码识别.xml,
baike.sxlbl.com验证码识别.xml,
china.alibaba.com验证码识别.xml,
dfrxb.com验证码识别.xml,
hfzs.cn验证码识别.xml,
my.home.new.cn验证码识别.xml,
passport.cntv.cn验证码.xml,
pconline验证码.xml,
phone.10086.cn验证码识别.xml,
tongxue.com验证码识别.xml,
valve365.com验证码识别.xml,
口碑验证码识别.xml,
上海热线图片识别.xml 等。更多的大家可供试验,成功识别的网站欢迎评论留言。
2011-03-21更新:我们已将该功能做成火车采集器的插件,可成功运用到火车采集器2010版中,旗舰版企业版用户可以直接免费使用,请直接向您所属客服索要该识别插件。 详细内容见: 火车采集器通用OCR识别.NET插件(03-21更新 )



标签: 验证码识别 通用验证码识别 OCR验证码识别 通用OCR
火车采集器图片识别程序
作者:小文 发布于:2010-10-13 13:26 Wednesday 分类:其它资源
该工具可以配合火车采集器图片识别插件工具.该插件下载地址: http://board.locoy.com/?post=24

使用方法如下:
将该工具放在和火车采集器同目录下.否则不能运行.
请先输入图片地址,然后点击下载,则可以看到如图中的远程图片.然后,点击识别,程序会自动将数字分割.每个数字下边对应的是相应的识别值.如果图片中的数字和实际的不符,请在对应的文本框内写上正确的数字,然后点击ok按钮,程序会将该特征码保存,然后请再次点击识别.如果正确,则可以进行其它操作了.如果您一不小心添加了错误的标识码,没关系,请在对应的号码上双击,就可以将其删除掉.
当所有的数字识别均正确后,可以点击保存特征码,将已识别的保存在文件中.如果需要在火车采集器中使用,则需要将上边我们提到的插件启用,同时,将导出的特征码的文件命名为 image.txt,放在火车采集器程序的同目录下即可.导出的特征码,如果下次使用,可以使用加载特征码的功能加载.
PHP对escape的字符串进行解密
作者:小文 发布于:2010-8-28 12:53 Saturday 分类:其它资源
Escape是js 脚本的一种加密字符串的方式.具体详情可以参见http://www.w3school.com.cn/js/jsref_unescape.asp
有的网站会将中文字进行Escape编码,然后在显示时用unescape再进行转换.比如有这么一段代码
<title>广州公交查询-由%u91D1%u6CFD%u5927%u53A6到%u767E%u5F81%u79D1%u6280%u5927%u53A6的乘车路线</title>
这个是经过Escape编码的.我们需要在PHP中将其解密.在网上搜索后,得到加密和解密代码.
<?php
function unescape($str) { //这个是解密用的
$str = rawurldecode($str);
preg_match_all("/%u.{4}|&#x.{4};|&#d+;|.+/U",$str,$r);
$ar = $r[0];
foreach($ar as $k=>$v) {
if(substr($v,0,2) == "%u")
$ar[$k] = iconv("UCS-2","GBK",pack("H4",substr($v,-4)));
elseif(substr($v,0,3) == "&#x")
$ar[$k] = iconv("UCS-2","GBK",pack("H4",substr($v,3,-1)));
elseif(substr($v,0,2) == "&#") {
$ar[$k] = iconv("UCS-2","GBK",pack("n",substr($v,2,-1)));
}
}
return join("",$ar);
}
function phpescape($str){//这个是加密用的
preg_match_all("/[\x80-\xff].|[\x01-\x7f]+/",$str,$newstr);
$ar = $newstr[0];
foreach($ar as $k=>$v){
if(ord($ar[$k])>=127){
$tmpString=bin2hex(iconv("GBK","ucs-2",$v));
if (!eregi("WIN",PHP_OS)){
$tmpString = substr($tmpString,2,2).substr($tmpString,0,2);
}
$reString.="%u".$tmpString;
} else {
$reString.= rawurlencode($v);
}
}
return $reString;
}
?>
我们测试一下
echo unescape("由%u91D1%u6CFD%u5927%u53A6到%u767E%u5F81%u79D1%u6280%u5927%u53A6的乘车路线");
可以得到 由金泽大厦到百征科技大厦的乘车路线
Html实体字符转换
作者:小文 发布于:2010-8-28 12:45 Saturday 分类:其它资源
有时,我们采集的数据类似 "你好", 这些字符在源代码中是这个样子,但在网页中确是正常显示为中文.这类代码叫做html实体 ,我们可以通过PHP的内置函数,对其进行转换,以方便查阅.
php代码如下:
echo mb_convert_encoding("你好", "gb2312", "HTML-ENTITIES"); //输出:你好
mb_convert_encoding 用法可以参考http://cn.php.net/manual/zh/function.mb-convert-encoding.php
如果您使用php插件,可能需要添加 php_mbstring.dll 扩展.火车采集器中PHP插件的扩展添加方法请查看文章 http://board.locoy.com/?post=34
联系我们
联系电话
-
0551-62864156
QQ邮件订阅

最新评论
- industrialegy
<a href="http://www.... - inve
这个采集到的视频地址 应该不是真实地址... - 云南桥架厂
我能说这个妹不错么 - 密密麻麻
win10 64位,处理后会留下原压缩包... - 平行进口车
以前经常用火车,来支持一下。 - 天津网站建设
文章采集器,厉害了 - 骗子医院
这个可以试试! - qq昵称
这么好的帖子,必须顶起来!! - 哈尔滨舒家网
试用一下,看是否能用。希望能用。火车头业... - 誉非
这个下载下来是安装程序,不是视频教程啊。
