
v7版本中PHP环境的修改
作者:小文 发布于:2012-7-26 17:33 Thursday 分类:常见问题
火车采集器支持php插件对数据进行处理。php插件的原理简单,是通过调用命令行的php.exe,对数据进行处理。v7版本的php目录为 System\PHP 。
采集器默认的php环境可能会无法满足用户的需要。这时,您可以更换您自己的php环境。需要注意的是php的工作目录是 System\PHP ,您可以直接将自己的php环境复制过来。注意的是该目录下的interface.php文件必须要保留。在更换完成后,请检查一下php.ini,看配置中的各种相对目录是否正确。测试无误后就可以使用了。
标签: php
v7版计划任务增加cron表达式测试工具
作者:小文 发布于:2012-7-20 10:34 Friday 分类:功能介绍
v7版本的计划任务基于cron表达式。因此,某些设置可能会无法直接达到,如每间隔120分钟无法在分钟里设置,可以设置成每间隔两小时。不能设置每间隔25个小时,可以设置每间隔一天。等等。下次更新中,计划任务将增加最近的几次运行时间,方便用户查看。以下附件就是基于此的小工具。
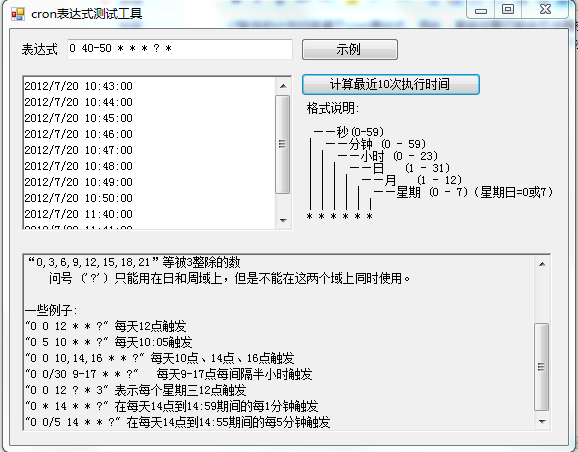
标签: cron
关于标签组合功能的使用说明
作者:小文 发布于:2012-7-18 9:41 Wednesday 分类:功能介绍
v7版本增加了一个标签组合的功能,许多朋友在使用中发现组合的结果和自己想要的结果不一致,下面我来说明一下该功能的使用。
1.标签组合组合的是文件下载前的内容
有的朋友发现,a标签中下载了某个文件,原始地址是aaa,下载后或是探测的地址为bbb,那么,如果您在b标签中组合使用a标签,a标签的值是aaa.为何使用这种处理方法,是因为文件下载是在标签组合之后进行的。如何达到标签内容是文件下载完后的结果呢?可以新建一个标签,选“自定义固定格式数据”,将您标签组合的内容放进去。这里的替换会在文件下载后执行。
2.内容页标签循环采集并添加为新记录
如果组合的两个标签都是内容页标签,这两个标签在组合时,会按循环数最大的记录产生新的同样数目的循环记录。如果某个标签的循环数较少,则新产生的标签中该标签的值为空。例如标签a,b组合生成标签c。a的循环数是5,b的循环数是3,则会生成5个c,其中,前3个标签的值分别是a,b一一对应的。最后两个值中,b的值为空。假设a的值是11,22,33,44,55,b的值为aa,bb,cc.c是由[标签:a][标签:b]组合, 则产生的c的值为11aa,22bb,33cc,44,55.
3.列表页标签和内容页标签组合
如果两个标签中一个是内容页,一个是列表页,则内容页是会参加第2条中的循环处理,在这个过程中列表页当作一个字符串处理。合并完成后,程序会再进行数据处理操作。最后,组合标签中的列表页标签内容将被替换成实际的值。组合后的结果中,可以再提取下载。比如内容页a和列表页b组合生成c,其中a的值为11,22,22,b的值为bb,那么,c第一次组合结果是 11[标签:b],22[标签:b],33[标签:b],然后进行数据处理。如果b的值是bb,那么最后的结果就可能是11bb,22bb,33bb.
有的朋友可能会说,干嘛将这个功能搞这么复杂的。其实,这个功能主要是为第一条的功能使用的,其它的组合方式可能会产生和原想法不一样的结果。建议大家不要滥用这个功能,不要将它想像成万能的。
E商统计预览版
作者:小文 发布于:2012-7-3 16:25 Tuesday 分类:开发计划
E商统计是一款用于抓取淘宝,天猫,拍拍,卓越等网店商品信息并进行分析的统计软件。它可以按关键字,按栏目对指定的商品进行抓取,也可以对指定的网店销售情况进行抓取分析。还可以对商品的交易信息,评论信息进行抓取和统计。它支持将抓取的数据导入其它的数据库或是网站,是网店数据分析的良好工具。该软件目前完成的功能有:搜索抓取和导出结果为excel.以下是该软件的操作方法:
1.软件的安装
打开火车头数据采集平台软件,在扩展菜单,扩展管理中安装E商统计即可。
2.软件的使用。
a.在分组上右键新建任务
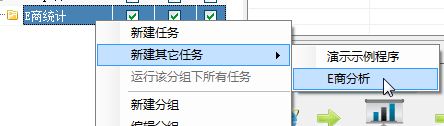
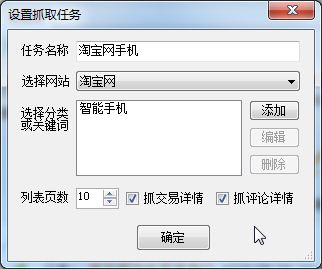
b.首先设置任务名,然后设置要抓取的关键词,点添加后会出现内置浏览器
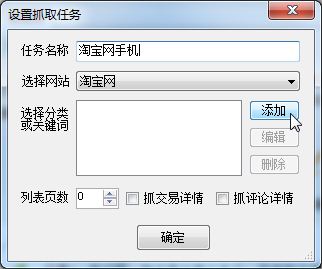
c.如图,在淘宝搜索后,点击确定
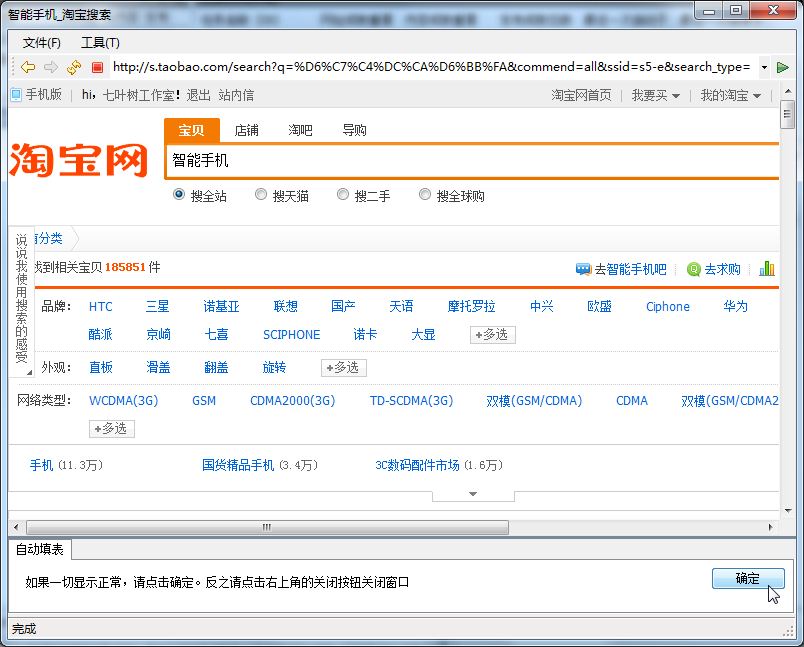
d.任务中就会添加了一个关键词,一个任务可以添加多个关键词,然后可以选是否采详细交易或评论
e.开始运行任务
f.任务运行过程

g.任务运行完成后,可以导出结果到Excel
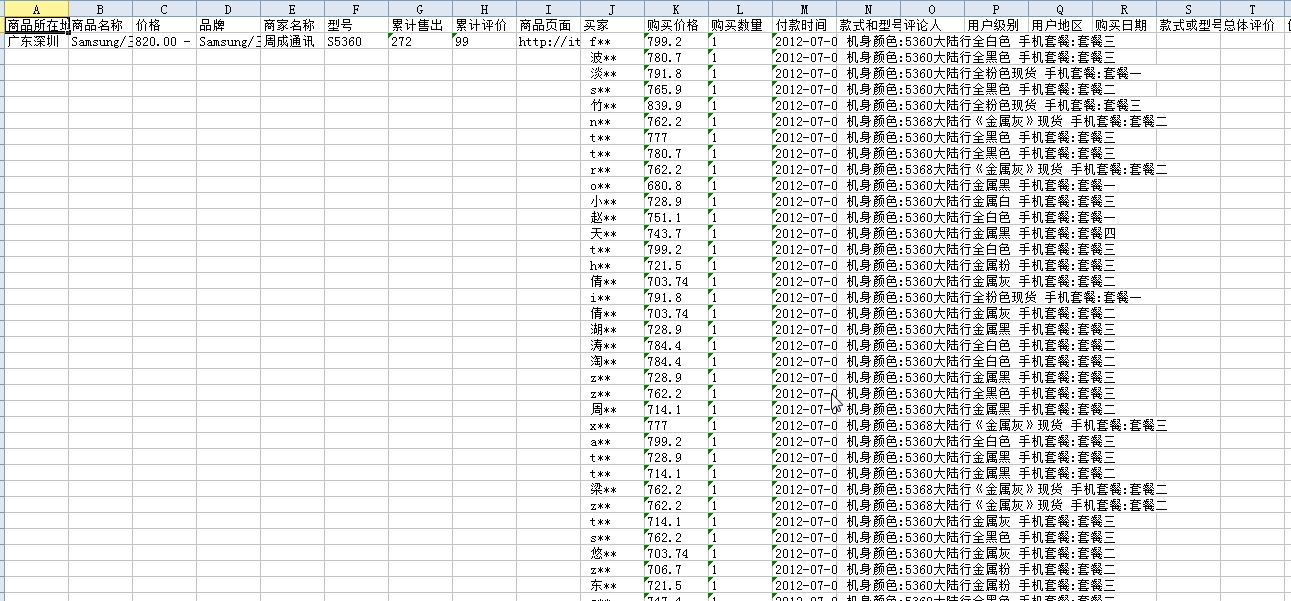
h.最后导出的结果,该结果在附件中包含。
关于部分服务器Head方法无法探测文件功能的解决办法
作者:小文 发布于:2012-6-1 9:31 Friday 分类:常见问题
火车采集器在探测文件真实地址过程中,会使用head方法请求下载地址,如果对方服务器返回禁止,程序会使用get方法去下载并探测下载地址,如果对方服务器返回200但是结果是错误的,采集器就可能无法获取到真实的下载地址。对于此情况,需要设置一个全局参数来对该网站只使用get探测文件地址方法。处理办法是
1.火车采集器升级到7.4.6.1版本
2.使用fiddler分析一下采集器探测下载的网址,提取网址中的域名。如www.locoy.com
3. 打开Configuration目录下的FileDetect.txt文件,如果没有,请新建一个.在打开的文件中输入域名 www.locoy.com ,如果是多个域名,每行一个。记得在文件的最后边再输入一个换行。保存文件。
4.重启采集器,即可以正常使用。
标签: 探测
联系我们
联系电话
-
0551-62864156
QQ邮件订阅

最新评论
- industrialegy
<a href="http://www.... - inve
这个采集到的视频地址 应该不是真实地址... - 云南桥架厂
我能说这个妹不错么 - 密密麻麻
win10 64位,处理后会留下原压缩包... - 平行进口车
以前经常用火车,来支持一下。 - 天津网站建设
文章采集器,厉害了 - 骗子医院
这个可以试试! - qq昵称
这么好的帖子,必须顶起来!! - 哈尔滨舒家网
试用一下,看是否能用。希望能用。火车头业... - 誉非
这个下载下来是安装程序,不是视频教程啊。
